Apache Spark-A Brief Overview

What is Apache Spark ?
- Meant for faster Cluster computing framework.
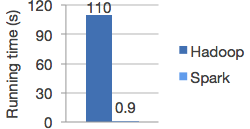
- Spark enables applications in Hadoop clusters to run up to 100 times faster in memory and 10 times faster even when running on disk.
- Enable to write application in Java, Scala or python.
- Big Data Processing framework
- Provide comprehensive, unified framework to manage big data processing requirements with a variety of data sets that are diverse in nature. Eg : Google – 100Pb, eBay – 100Pb,Facebook-600 Tb per day.
- Spark is being adopted by major players like Amazon, eBay, and Yahoo!.
Hadoop and Spark
- Hadoop is one of the big data processing technologies present since 10 years.
- Use linear model to process data.
- Use MapReduce cycle and disk writes to process data hence slow.
- Spark provide InMemory data processing in Cluster.
Spark Features
- Spark holds intermediate results in memory rather than writing them to disk which is very useful especially when you need to work on the same dataset multiple times.
- Spark operators perform external operations when data does not fit in memory.
- Provide High level API in Scala, Java and Python to improve developer productivity and consistent architecture model for Big Data processing.
- Till now fastest open source engine for sorting a petabyte.
Spark at Yahoo
- One for personalizing news pages for Web visitorsAnother for running analytics for advertising.
- Another for running analytics for advertising.
- Yahoo has two Spark projects in the works.
- To achieve this Yahoo (a major contributor to Apache Spark) wrote a Spark ML (machine learning) algorithm in Scala.
- With just 30 minutes of training on a large, hundred million record data set, the Scala ML algorithm was ready for business.
You may also like :
Basic steps to implement ASP dotnet MVC using Entity Framework Code First approach
SQL Query to Release lock on database
How to change URL withought page postback
Csharp Code to make call By connecting you phone to PC
BE Electronics ETC IT Computer Project Titles - Group 1
SQL Query to Split string by specific seperator
Simple Page Method in asp.net
Error 720 Resolution
Queries in LINQ to DataSet
BEWARE-XSS THIEVES ARE LOOKING FOR YOU
how to search date within range in c Sharp dot net and mssql
You may also like :




















